
本研究使前馈神经网络的小批量MCMC采样变得更加可行。为此,提出了一种闭塞Gibbs抽样方案对参数子组进行抽样。通过划分参数空间,无论层宽如何都可以进行采样。通过减少更深层的建议差异,也可以缓解随着深度的增加而消失的接受率。增加非收敛链的长度可以提高分类任务的预测准确性,因此避免接受率消失,从而实现更长的链运行具有实际的好处。此外,非收敛链的实现有助于预测不确定性的量化。如何在增强数据存在的情况下对前馈神经网络进行小批量MCMC采样是一个有待解决的问题。
范围。本文通过将前馈神经网络的参数分成子群,使其更适合于对其参数进行近似MCMC采样。此外,它还指出了这种抽样方法的几个优点。
动机。为什么要考虑近似MCMC采样算法用于深度学习?答案源于MCMC的一般优点,即不确定性量化。这项工作展示了神经网络参数的近似MCMC采样如何量化分类问题中的预测不确定性。
的局限性。有几个障碍阻碍了MCMC在深度学习中的应用;举三个臭名昭著的问题:低接受率、高计算成本和缺乏收敛性。参见Papamarkou et al.(2022)的相关综述。
的潜力。本文的经验证据表明,对深度学习中近似MCMC的看法不那么不屑一顾。首先,考虑到神经网络结构并将参数空间划分为更小的参数块的采样机制保持了更高的接受率。其次,神经网络参数的小批量MCMC采样缓解了大数据带来的计算瓶颈。用于预测和评估预测性能的贝叶斯边缘化在计算上也很昂贵。然而,贝叶斯边缘化在测试点和马尔可夫链长度上是令人尴尬的并行化。第三,如果通过神经网络评估预测不确定性是预期的结果,那么参数空间中的MCMC收敛被视为踏脚石,而不是这种结果的先决条件。一个不收敛的马尔可夫链获得了有价值的预测信息。事实上,已有研究表明,贝叶斯神经网络中的后验预测密度可以限制在参数空间的一个不对称子集(Wiese et al. 2023)。
的贡献。本文的主要贡献是提出了前馈神经网络的小批量阻断Gibbs采样方法,并通过实验验证了这种采样方法的可行性。如果不优化先前的规格,则通过将参数空间划分为小块来克服消失的接受率。从前馈神经网络的采样方案的实验研究中得出了一些观察结果。首先,观察到划分参数空间允许在宽度增加的情况下从参数空间中采样。其次,随着深度的增加,这种划分通过减少提案方差来缓解更深层次的接受率消失。第三,指出增加批大小如预期的那样增加预测精度,只要批大小不变得大到产生消失接受率的点。第四,证明了让非收敛链的实现运行更长时间可以提高预测精度。第五,证实了在增广数据存在下的采样是一个有待解决的问题。最后,证明了非收敛链实现有助于预测不确定性的量化。
论文结构。本文的结构如下。第2节回顾了深度学习的MCMC文献。第3节修正了一些基本知识,包括贝叶斯多层感知器(MLP)模型和阻塞吉布斯采样。第4节介绍了一种更精细的节点阻塞Gibbs (FNBG)算法来采样MLP参数。第5节利用FNBG采样将mlp拟合到三个训练数据集,并对三个相关的测试数据集进行预测。在第5节中,对mlp中近似MCMC的范围进行了大量观察。第六部分对本文进行了总结,并对未来的研究方向和局限性进行了讨论。
本节回顾了神经网络中MCMC的文献。关于该主题的其他一些评论也存在,例如Titterington (2004), Wenzel等人(2020),Izmailov等人(2021),Papamarkou等人(2022)。在上述评论之后出现的神经网络的新的MCMC发展,包括在这里。
针对神经网络的MCMC算法的研究方向主要有四个。首先,将序贯蒙特卡罗算法和可逆跳跃蒙特卡罗算法应用于前馈神经网络。在第二波发展中,小批量MCMC算法成为主流方法。最近,焦点已经转移到吉布斯采样算法和贝叶斯神经网络的先验构造。
在神经网络MCMC发展的早期阶段,SMC和可逆跳跃MCMC被应用于mlp和径向基函数网络(Andrieu et al. 1999;de Freitas 1999;Andrieu et al. 2000;de Freitas et al. 2001)。有关贝叶斯神经网络方法的历史背景,请参见Titterington (2004), Papamarkou等人(2022)。
在minibatch MCMC中,目标密度在数据的一个子集(minibatch)上进行评估,从而避免了基于整个数据的MCMC迭代的计算成本。随机梯度MCMC (SG-MCMC)算法是一种利用目标密度梯度的小批量MCMC算法。Welling和Teh(2011)采用了小批量的概念来开发随机梯度朗格万动力学(SG-LD)蒙特卡罗算法,这是SG-MCMC的第一个实例。Chen等人(2014)引入了随机梯度哈密顿蒙特卡罗(SG-HMC),这是SC-MCMC的另一个实例,并将其应用于推断拟合到MNIST数据集的贝叶斯神经网络的参数(Lecun et al. 1998)。
SG-LD和SG-HMC是两种SG-MCMC算法,它们开创了机器学习中近似MCMC的研究。从那以后,SG-MCMC的几个变种出现了。Gong等人(2019)提出了一种SG-MCMC方案,该方案通过状态相关的漂移和扩散来推广哈密顿动力学,并证明了该方案在卷积和循环神经网络上的性能。Zhang等人(2020)提出了周期性SG-MCMC,这是具有周期性步长计划的SG-LD的缓和版本。此外,Zhang等人(2020)展示了周期性SG-MCMC在ResNet-18 (He et al. 2016)上的性能,该ResNet-18与CIFAR-10和CIFAR-100数据集(Krizhevsky和Hinton 2009)相匹配。Alexos等人(2022)引入了结构化的SG-MCMC,即SG-MCMC和结构化变分推理的结合(Saul and Jordan 1995)。结构化SG-MCMC采用SG-LD或SG-HMC从因式变分参数后验密度中抽样。Alexos等人(2022)在ResNet-20 (He et al. 2016)架构上测试了结构化SG-MCMC的性能,该架构适用于CIFAR-10、SVHN (Netzer et al. 2011)和时尚MNIST (Xiao et al. 2017)数据集。
各种吉布斯抽样算法最近被开发出来,考虑到大规模的推理。Bouchard-C?té等人(2017)引入了粒子Gibbs分裂合并采样器,并探索了其在四个高维数据集上的性能。基于乘数优化算法的交替方向方法的分离式吉布斯采样器已经被开发出来,用于在大型数据集上执行贝叶斯推理,并可能在高维模型上执行贝叶斯推理(voo et al. 2019, 2022)。尽管到目前为止还没有应用到神经网络中,但这样的粒子吉布斯和分裂吉布斯采样器表明,将参数或辅助变量分成子组的想法提供了一种解决大规模推理问题的方法。
Grathwohl等人(2021)引入了Gibbs-with-gradients (GWG)采样器,这是一种用于具有离散变量的概率模型的通用且可扩展的近似采样策略。GWG与自适应Gibbs采样器有关(?atuszyński et al. 2013)。Grathwohl等人(2021)在受限玻尔兹曼机(Boltzmann machines)上训练了GWG,受限玻尔兹曼机是一种生成式随机神经网络,并将GWG与阻塞吉布斯采样进行了比较,使用后者的样本作为基本事实。
Minibatch MCMC(第2.2节)和Gibbs采样器(目前的第2.3节)并不构成两个相互排斥的算法类。为了详细说明小批量MCMC和吉布斯采样器所涉及的本体,提出了三点意见。首先,HMC可以表示为吉布斯采样器(Girolami and Calderhead 2011)。其次,阻塞Gibbs采样中的每个参数子组可以通过MCMC采样步骤进行更新。例如,如果通过Metropolis-Hastings (MH), Langevin dynamics (LD)或HMC采样步骤更新每个参数子组,则相应的采样器称为MH-within- gibbs, LD-within- gibbs或HMC-within- gibbs。第三,软件文档中使用术语SG-LD和SG-HMC来指代在一次扫描或分层中对所有神经网络参数进行采样的算法。然而,当分层进行参数采样时,SG-LD和SG-HMC是误称,正确的采样器名称分别是SG-LD-within- gibbs和SG-HMC-within- gibbs。
神经网络的先前规范是在21世纪前夕考虑的,参见Papamarkou等人(2022)的相关评论。随着脊波先验(Matsubara et al. 2021)和功能先验(Tran et al. 2022)的引入,神经网络先验规范的研究最近重新兴起。Tran等人(2022)提出的功能先验被设计用于在贝叶斯深度学习中执行近似MCMC采样。
摘要
1 介绍
2 文献综述
3.预赛
4 方法
5 实验
6 未来的工作
7 软件和数据
参考文献
致谢
作者信息
道德声明
附录
搜索
导航
#####
本节修订了两个主题,用于监督分类的贝叶斯MLP模型(第3.1节)和阻塞吉布斯抽样(第3.2节)。对于贝叶斯MLP模型,给出了参数后验密度和后验预测概率质量函数。阻塞Gibbs采样为开发第4节中从MLP参数后验密度采样的算法提供了一个起点。
MLP是一个前馈神经网络,包括一个输入层、一个或多个隐藏层和一个输出层(Rosenblatt 1958;Minsky and Papert 1988;Hastie et al. 2016)。对于固定的自然数,索引表示层。特别地,指的是输入层,指的是其中一个隐藏层,指的是输出层。设第j层的节点数,设每层节点数的序列。表示在第j层具有隐藏层和节点的MLP。
在第j层有隐藏层和节点的An递归定义为
(3.1) (3.2)
对。输入数据点被传递到输入层,在第一个隐藏层中产生向量。第j层的参数由权重和偏置组成。权重矩阵有行和列,偏差向量有长度。到第j层的所有权重和偏差都表示为。激活函数按元素方式应用于预激活向量,并返回后激活向量。连接all,给出一个长度的参数向量。
图1
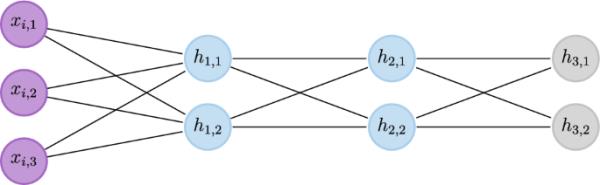
的图形可视化紫色、蓝色和灰色节点分别对应输入数据、隐藏层后激活和用于预测的输出层(softmax)后激活
表示权重矩阵的第(k, l)个元素。类似地,和对应于偏差、输入、预激活和后激活的第k个坐标。
mlp通常被可视化为图形。例如,图1显示了一个图形表示,它有一个带有节点的输入层(紫色),两个每个节点的隐藏层(蓝色)和一个带有节点的输出层(灰色)。紫色节点表示观察到的变量(输入数据),而蓝色和灰色节点表示潜在变量(后激活)。
设为训练数据集。每个训练数据点包括一个输入和一个离散输出(标签)。此外,设(x, y)为由输入和标签组成的测试点。考虑的监督分类问题是在给定测试输入x和训练数据集的情况下预测测试标签y。使用输出层有节点的An,使用softmax激活函数来解决这个问题。输出层的softmax激活函数表示为。
假设训练标签是一个具有事件概率的分类pmf的s个独立抽取的结果,其中为参数集。由此可知,该模型在监督分类中的似然函数为
(3.3)
式中为训练输入,为指标函数。我们感兴趣的是从参数后验密度中抽样
(3.4)
给定Eq.(3.3)的似然函数和参数先验。为简洁起见,参数后验密度交替表示为。
通过积分我们的参数,得到给定测试输入x和训练数据集的测试标签y的后验预测pmf
(3.5)
式中为Eq.(3.3)对(x, y)的似然函数,为Eq.(3.4)的参数后验密度。Eq.(3.5)中的积分可以通过蒙特卡罗积分近似,得到近似后验预测pmf
(3.6)
其中是由参数后验密度得到的马尔可夫链实现。最大化Eq.(3.6)的近似后验预测pmf得到预测
(3.7)
用于测试标签。
具有输出层节点的MLP模型的似然函数如Eq.(3.3)所示,适用于带有类的多类分类。对于涉及两个类的二元分类,Eq.(3.3)与具有输出层节点的MLP有关。有一种基于单一输出层节点的MLP模型的备选似然函数,可用于二值分类;详情见Papamarkou et al.(2022)。
阻塞Gibbs抽样算法对两个或多个参数的组(块)进行抽样,这些参数以所有其他参数为条件,而不是对每个参数单独抽样。参数组的选择影响收敛速度(Roberts and Sahu 1997)。例如,将参数空间分解为统计上独立的相关参数组可以加快收敛速度。
为了从拟合到训练数据集的模型的参数后验密度中采样,阻塞Gibbs采样算法利用MLP参数的分区。由于划分,参数子集是两两不相交且满足的。在不损失一般性的情况下,假设的每个子集都是完全有序的。对于任意的(c, q),以下使用简写符号。所以这个向量是。
在这种设置下,“附录a”总结了被阻止的吉布斯抽样。在迭代t时,对于每一个,阻塞Gibbs抽样算法从相应的条件密度中抽取一个参数组样本。换句话说,在每次迭代中,从每个参数组的条件密度中抽取样本,这些条件密度以其他参数组和训练数据集的最新值为条件。
本节介绍了监督分类中mlp的阻塞Gibbs抽样算法。MLP参数块通过将参数链接到MLP节点来确定,如第4.1节和4.2节所述,并在第4.3节和4.4节中举例说明。
小批量和参数阻塞使所提出的吉布斯采样器成为可能。阻塞吉布斯采样通常是由通过近最优或最优参数分组获得的提高的收敛率所驱动的。虽然低收敛速度是深度学习中MCMC的一个问题,但接近于零的接受率构成了一个更直接的问题。换句话说,不混合是比缓慢混合更紧迫的问题。通过一次更新一小块参数,而不是通过单个步骤更新所有参数,每个块特定的接受率都从零开始。因此,小批量阻塞吉布斯采样为深度学习中消失的接受率提供了一个解决方案。当然,天下没有免费的午餐;提高接受率是以每个吉布斯步骤的计算代价为代价的,吉布斯步骤由附加的条件密度采样子步骤组成。
在典型的SG-LD-within-Gibbs和SG-HMC-within-Gibbs软件实现中,每个MLP层形成一个参数块(见第2.3节)。对按MLP层分组参数的一个警告是,参数块大小取决于层宽度。因此,一个参数块可能很大,包含数百或数千个参数,这样就无法解决接受率低的问题。本文的闭塞Gibbs采样器按MLP节点对参数进行分组,并允许在每个节点内进一步将参数划分为更小的块,从而控制每个块的参数数量。
虽然结构化SG-MCMC (Alexos et al. 2022)也将参数空间分割成块,但它使用参数块来分解变分后验密度。因此,结构化SG-MCMC旨在通过分解近似参数后验密度来解决低接受度和缓慢混合的问题。在这里,闭塞的吉布斯采样器依靠更精细的参数分组来分解精确的参数后验密度。Minibatching是本文屏蔽Gibbs采样器所采用的唯一一种近似,它是与数据相关的近似,而不是与MLP模型相关的近似。
用于前馈神经网络的更精细的节点阻塞吉布斯采样器,正如目前设想的那样,是一个小批量mh - in-Gibbs采样器。主要思想是更新一个相对较小的神经网络参数块,从而使其能够接受minibatch MH提出的状态。由于每个参数块采用minibatch MH采样步骤,因此采样器是无梯度的。选择这种无梯度的方法是为了限制计算成本。根据计算资源的可用性,可以采用SG-LD或SG-HMC抽样步骤代替小批量MH抽样步骤。
阻塞吉布斯采样提出了如何从条件密度中采样每个参数块的问题。mlp的这种条件密度不能以封闭形式提供。相反,可以采取单一的Metropolis-Hastings步骤从条件密度中抽取样本。在这种情况下,得到的阻塞吉布斯抽样算法被称为阻塞吉布斯内大都会(MWBG)抽样。
在MWBG迭代t时,可以从以迭代状态为中心的各向同性正态建议密度中采样参数块的候选状态,其中为单位矩阵,为块中参数的个数,为块的建议方差。候选状态的接受概率由式给出
(4.1)
式中为交叉熵损失函数。有关接受概率的更多细节见“附录A”。

算法1总结了精确的MWBG采样。为了使算法1适用于大数据,可以使用minibatching,将所有的实例替换为batch(严格的子集);所得到的近似MCMC算法被称为“小批量MWBG采样”。
大数据和大模型对MCMC采样方法在深度学习中的适应性提出了挑战。Minibatching提供了一种将MCMC应用于大数据的方法。目前尚不清楚如何将MCMC应用于包含数千或数百万个参数的大型神经网络模型。小批量MWBG采样通过对子集数据和子集模型参数进行类比,提出了一种改进方法。由于数据批次降低了每次Gibbs采样迭代的数据维数,参数块降低了每次Metropolis-within-Gibbs更新的参数维数。
在有n个参数的an中,第j层包含两个参数,一个是权重,一个是偏置。因此,如果参数按层分组,则层j的块包含参数。j层块内的参数数随j层节点数线性增长,随层节点数线性增长。
如果参数按节点分组,则j层的每个节点块包含,其中一个是权重,一个是偏差。j层节点块的参数个数不依赖于j层节点的个数,而是随层节点的个数线性增长。基于MLP节点参数分组的MWBG采样(算法1)被称为“(Metropolis-within-)node-blocked- gibbs (NBG)采样”。
通过将j层节点的参数分成子组,可以生成更细、更小的参数块。在这种情况下,j层中每个节点的每个更细的参数块都包含参数。如果选择的超参数是的线性函数,则j层中每个节点每个更细块的参数数既不取决于j层的节点数,也不取决于层中的节点数。基于每个节点更细参数分组的MWBG采样(算法1)被称为“(Metropolis-within-)finer-node-blocked- gibbs (FNBG)采样”。
参数块越小,每块的接受率越高,FNBG采样的计算复杂度也越高。因此,每个块的参数数量调节了接受率和计算复杂性之间的权衡。作为一个实用的指导方针,每个块的参数数量可以通过逐步减少来调整,直到达到非消失的接受率,以便使采样成为可能。采样的最优参数块大小问题类似于随机优化的最优学习率问题。这两个问题都提出了超参数优化问题,可以主要从工程角度来解决,而不是从理论解决方案来解决。
图1所示的架构提供了一个简单的示例,展示了基于层、基于节点和更精细的基于节点的参数分组(更简单地称为“层阻塞”、“节点阻塞”和“更精细的节点阻塞”)。需要提醒的是,基于节点的更细分组是指在每个节点内将参数分组为更小的块。图2显示了的有向无环图(DAG)表示,用参数注释和一个由单个节点组成的层(表示标签)扩展了图1。黄色形状表示参数;黄色圆圈和方框对应偏差和权重。黄框遵循板模型的说明性视觉惯例,每个框代表一组权重。紫色节点表示观察到的变量(输入和输出数据),而蓝色和灰色节点表示潜在变量(后激活)。
图2
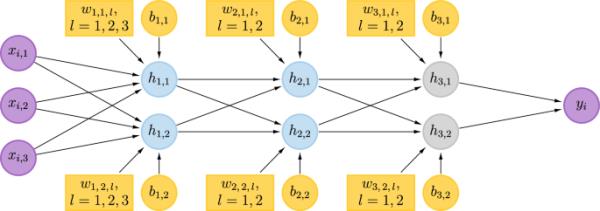
基于节点的架构参数阻塞的可视化演示。MLP表示为DAG。黄色节点和黄色板块对应偏差和权重。在DAG中,为每个蓝色隐藏层节点和灰色输出层节点分配一个黄色父节点的参数块
Layer-blocking将包含20个参数的集合划分为3个包含参数的块。例如,第一个隐藏层诱导块,其中。
节点阻塞将20个参数的集合划分为6个块,与隐藏层和输出层节点的数量相同。隐藏层或输出层中的每个蓝色或灰色节点都有自己独特的黄色权重和偏差父节点集。参数根据共享亲子关系分组。例如,block的参数,有一个共同的子节点。
参数块的接受概率需要进行似然函数评估。不可能因式分解条件密度来实现计算效率更高的块更新。例如,如图2所示,由于分层MLP结构,第一层节点引起的块变化会通过后续层传播,从而禁止了条件密度的因式分解。更正式地说,每对基于节点的参数块形成一个v结构,标签(紫色节点)作为后代。由于观察到训练标签,这样的v结构被激活,因此给定标签,任意两个基于节点的参数块都不是条件独立的。
作为对第1层设置的更精细节点阻塞的演示。对于,块和在节点内生成。类似地,块和在节点内生成。
回顾一下这个简单的例子,基于层的分组在第1层产生一个包含8个参数的块,基于节点的分组在第1层产生两个包含4个参数的块,而更精细的基于节点的分组在第1层产生四个包含2个参数的块。因此,说明了每个节点更细的块提供了一种减少每个吉布斯采样块的参数数量的方法。
在作为一个小示例来描述精细节点阻塞的基础知识之后,将使用更广泛的体系结构来详细说明每个节点的较小块的实际相关性。An被拟合到第5节中的MNIST(和FMNIST)训练数据集。a包含8180个参数,其中7850、110、110和110分别在第一隐藏层、第二隐藏层、第三隐藏层和输出层有子节点。
因此,layer-blocking for包含四个大小的参数块。由于区块大小较大,因此块的Metropolis-within-Gibbs更新的接受率为零或接近于零。尽管每个区块的大小都比1小近两个数量级,但块大小可能大到足以产生吉布斯内的大都会更新,但接受率极低。
节点阻塞对于第一隐藏层的每个节点需要一个785个参数的块,对于第二、第三隐藏层和输出层的每个节点需要一个11个参数的块。因此,节点阻塞解决了除第一个隐藏层外所有层的块更新与大参数块相关的低接受率问题。
的隐藏层或输出层的节点不需要进行更精细的节点阻塞,因为这些层中的每个块只包含11个基于节点阻塞的参数。另一方面,更精细的节点阻塞对于属于第一个隐藏层的节点是有用的,因为与这些节点相关的每个块包含大量的785个参数。通过设置,在第一个隐藏层生成较小的块(每个块由78或79个参数组成)。因此,更精细的节点阻塞将第一个隐藏层中的块大小与输入数据维度分开,从而可以减小块大小,从而提高接受率。
通过小批量FNBG采样,对深度学习中近似MCMC的几个特征进行了实证观察。在本节的实验中,对mlp的参数进行采样。使用了三个数据集,即模拟噪声版本的exclusive-or (Papamarkou等人,2022),MNIST (Lecun等人,1998)和时尚MNIST (Xiao等人,2017)。为简洁起见,独占或和时尚MNIST被缩写为XOR和FMNIST。表1显示了使用的数据集和拟合的mlp之间的对应关系。
表1实验中使用的数据集和与这些数据集拟合的mlp
带噪声的异或训练和测试数据集见“附录B”图9。对应灰色点和黄色点的(0,0)和(1,1)的随机扰动映射为0(圆)。此外,紫色点和蓝色点对应的(0,1)和(1,0)的随机扰动映射到1(三角形)。关于噪声异或模拟的更多信息可以在Papamarkou等人(2022)中找到。
首先对MNIST和FMNIST图像进行重构,将其从矩阵转换为长度向量,然后对其进行标准化。这个图像重塑解释了为什么适合MNIST和FMNIST的模型的输入层宽度为784。
如Papamarkou等人(2022)所述,通过基于二元交叉熵的似然函数对噪声异或进行二值分类。MNIST和FMNIST的多类分类通过Eq.(3.3)给出的基于交叉熵的似然函数进行。
在表1的每个MLP的每个隐藏层上应用s型激活函数。的输出层也采用了s型激活函数,符合二值分类所采用的似然函数。根据多类分类的似然函数(3.3),在输出层应用softmax激活函数。同样的模型被拟合到MNIST和FMNIST数据集。
表1所示的各MLP模型参数均采用正态先验。因此,相对较高的方差(等于10)被先验地分配给每个参数。
NBG采样是在对有噪声的异或训练集进行拟合时进行的,而FNBG采样是在对MNIST和FMNIST训练集进行拟合时进行的。因此,参数在和中按节点分组,而在第一个隐藏层中每个节点形成多个参数组,详见4.4节。参数从第二个隐藏层开始按节点分组。表1中的三个mlp都是相对较浅的神经网络。但是,与和相比,其输入层宽度要大两个数量级。因此,MNIST和FMNIST输入数据的高维要求在的第一个隐藏层进行更精细的节点阻塞。另一方面,噪声异或输入数据的较小维度意味着在of或of的第一个隐藏层中不需要每个节点更精细的块。
为每个参数块选择一个正常的建议密度。每个提议密度的方差是一个超参数,因此可以针对每个参数块分别调整提议步骤的大小。已进行了FNBG初步试运行,以调整提议的差异。在这个预训练阶段,建议方差最初被设置为跨所有参数块的一个相对较高的值。随后,每个隐藏层中的块的建议方差在更深的层中被减小到更小的值,直到达到非消失接受率。
马尔可夫链是对有噪声异或实现的,而由于计算资源的限制,对MNIST和FMNIST都实现了马尔可夫链。每个链实现运行110000次迭代,其中10000次被丢弃。因此,每个链实现都保留了燃烧后的迭代。接受率是根据每个链的所有100000次燃烧后迭代计算的。
对于每个测试集的每个数据点,根据Eq.(3.6)计算后验预测pmfs的蒙特卡罗近似。为了减少计算成本,在式(3.6)中使用每个已实现链的最后迭代。
使用Papamarkou等人(2022)中提到的二元分类规则进行噪声异或预测。对MNIST和FMNIST的预测使用由Eq.(3.7)指定的多类分类规则进行。给定基于训练集的单链实现,对相应测试集中的每个点进行预测;然后,预测精度被计算为正确预测的个数除以测试集中的总点数。对于有噪声的异或测试集,给出了各实现链预测精度的平均值。对于MNIST和FMNIST测试集,报告了基于相应单链实现的预测精度()。
在接受率、预测精度和运行时间方面,对近似和精确NBG采样进行了说明性比较。近似和精确NBG采样之间的比较仅在噪声异或的情况下进行,因为由于接受率消失和高计算要求,精确MCMC对于MNIST和FMNIST示例是不可行的。
在四种情况下拟合到噪声异或训练集。对于场景1,近似的NBG采样以批量大小为100来模拟链。对于场景2,运行精确的NBG来模拟10条链。对于场景3,运行精确的NBG,直到获得10个链,每个链都有一个接受率。对于场景4,精确的NBG运行直到获得10个链,每个链都具有接受率。分别在场景3和场景4下共运行11条和23条链,得到满足每种场景接受率下限的10条链。
不建议开发一种依赖于某些接受率阈值作为链保留标准的抽样算法,因为这样的标准会在估计目标参数后验密度时引入偏差。本实验的目的是为了证明,避免过高的低接受率可以生成具有预测能力的链。
对于近似的NBG采样(场景1),建议方差设置为0.04。对于三个精确的NBG采样场景,提案方差被降低到0.001,以减轻在样本量(5000个训练数据点)相对于近似采样中使用的100个批大小增加的情况下接受率的下降。
图3
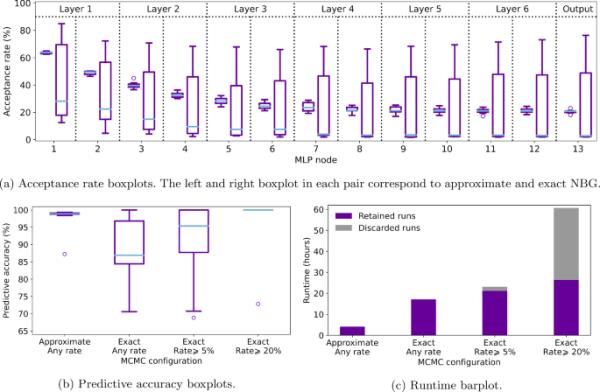
近似和精确NBG采样的比较。在四种情况下拟合噪声异或,每种情况获得10个链。场景1:批大小为100的近似NBG。场景2:精确的NBG。场景3:带有接受率的精确NBG。场景4:带有接受率的精确NBG。在方案3和方案4中接受率分别低于和低于接受率的链被丢弃,直到每种情况下达到10个链
图3a显示了在没有接受率下界条件(场景1和场景2)的情况下,近似和精确NBG采样的节点特定接受率的箱形图。对于的6个隐藏层和1个输出层中的13个节点,每一个都有一对箱形图。每对左右箱形图对应于近似和精确的NBG采样。蓝线代表中位数。
从图3a中得出三个经验观察结果。首先,根据(蓝色)中位数,近似NBG比精确NBG获得更高的接受率,尽管前者的建议方差高于后者(分别为0.04和0.001)。其次,从箱线图的四分位数范围来看,近似的NBG比精确的NBG获得更少的波动性接受率。随着神经网络深度的增加,精确NBG的接受率从接近到大约不等,在一些链实现中,由于困在局部模式中,表现出缺乏稳定性。第三,采收率随着深度的增加而降低。例如,在节点1和节点13中,精确的NBG的接受率中值分别为和。接受率随深度的衰减将在5.3节中进一步讨论。
图3b显示了所考虑的四种场景的预测准确度的箱形图。近似NBG的中位数预测精度为,四分位数范围集中在中位数附近,并且在10个链实现中有一个异常值()。不以接受率为条件的精确NBG和以接受率为条件的精确NBG比精确NBG具有更低的中位数预测精度(和)和更高的四分位数范围。以接受率为条件的精确NBG的中位数预测精度为;10个链实现中有9个产生精度,一个链给出的异常精度为。总的结论是,近似NBG比精确NBG具有预测优势,因为小批量采样确保了高预测精度和减少预测可变性方面的一致性。在高接受率的条件下,精确的NBG可以在玩具噪声异或示例的低参数和数据维度中产生近乎完美的预测精度,但稳定性和计算问题会出现,因为在获得具有所需接受率水平()的10条链之前,许多接受率接近零的链被丢弃。
图3c显示了所考虑的四种场景的运行时间(以小时为单位)的柱状图。紫色条表示每个场景保留的10个链的运行时,而灰色条表示由于未满足接受率要求而被丢弃的链的运行时。从紫色条之间的比较中可以看出,近似NBG比精确NBG的运行时间更短(对于相同长度的保留链),这是因为minibatching在每次近似NBG迭代时使用训练集的一个子集。场景3和场景4中的灰色条之间的比较表明,丢弃链的确切NBG运行时间随着接受率下界的增加而增加。通过对图3b和图c的共同观察,我们指出精确NBG的预测精度提高(由于更高的接受率下界)需要更高的计算成本。
基于Metropolis-Hastings接受机制的精确MCMC算法由于接受率消失和计算成本高而无法用于前馈神经网络。将参数空间分割成更小的块可以恢复更高的接受率,并且小批量MCMC采样减少了每个采样步骤的计算成本。由于对预测精度的影响相对较小,minibatch阻塞Gibbs采样使得以更低的计算成本遍历参数空间成为可能。从精确MCMC的不混合到近似MCMC的缓慢混合,可以提高预测精度。
图4显示了通过小批量NBG拟合噪声异或后实现的跨链平均接受率。其中,图4a显示了6个隐藏层和1个输出层中每个节点的平均接受率,图4b显示了这7个(6个隐藏层和1个输出层)的平均接受率。小批量NBG的批量为100个。在图3和图4中使用了相同的10条链。
图4
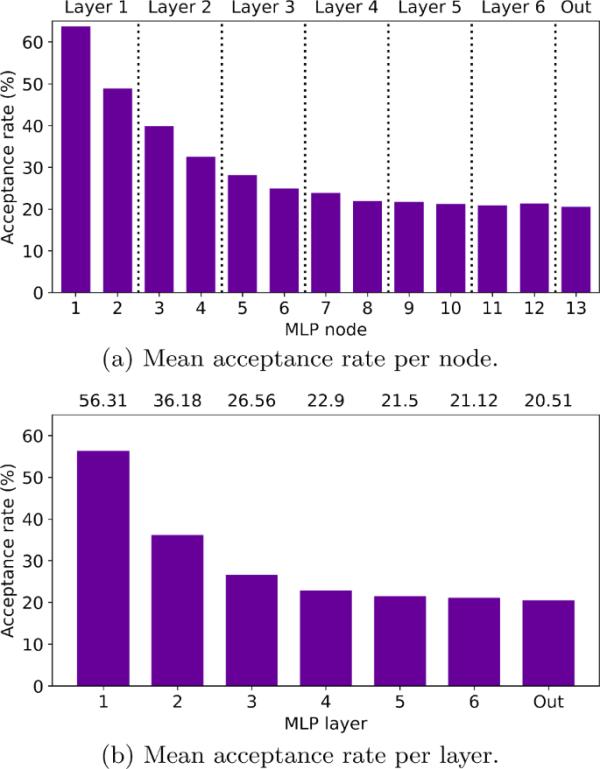
通过对参数进行小批量NBG采样,实现了10条链的平均接受率(每个节点和每层)。MLP适用于噪声异或。批量大小为100个
图3a和4a提供了特定节点接受率的另一种视图。前一个图通过箱形图和中位数表示这些信息,而后一个图则使用相关均值的柱状图。
图4表明,如果提案方差对于跨层的所有参数块是相同的,那么接受率会随着深度而降低。例如,从图4b中可以看出,隐藏层1、2和3的接受率分别为,和。
对跨层的所有参数块使用通用的建议方差会产生接受率的差异,较浅的层的接受率较高,而较深的层的接受率较低。这些差异在大数据或高参数维度下变得更加明显。例如,在MNIST或FMNIST情况下,在所有参数块中具有相同建议方差的采样参数是不可行的;第一个隐藏层的接受率很高,而在输出层的接受率几乎为零。FNBG采样能够减少更深层的建议方差,从而避免接受率随着深度的增加而消失。
“附录C”中的表5和表6举例说明了在MNIST和FMNIST的各自情况下,小批量FNBG采样参数的经验调整建议方差。批量大小分别为600、1800、3000和4200,分别对应于MNIST和FMNIST训练集。对于这四种批大小和每个训练集,在预训练过程中减少每层的提案方差,直到该层的接受率不是太低,然后使用预训练调整后的提案方差从链实现中计算相应层的接受率。表5和表6表明,如果提案差异在更深的层次中减少,那么接受率不会随着深度而消失。随着批量大小的增加,所有层的接受率都会下降,正如预期的那样,当从近似MCMC转向精确MCMC时。
作为表5的一部分,通过批量为3000的小批量FNBG采样拟合MNIST训练集,模拟了一条链。图5是由该链生成的,它包含一个轨迹图网格。图5的每一行都与的8180个参数中的一个有关。具体来说,第一、第二、第三、第四行分别对应隐藏层1的参数、隐藏层2的参数、隐藏层3的参数和输出层的参数。每一行显示一对每个参数的轨迹图;右边的轨迹图比左边的更缩小。右列中的所有轨迹图在其垂直轴上共享一个公共范围。
图5
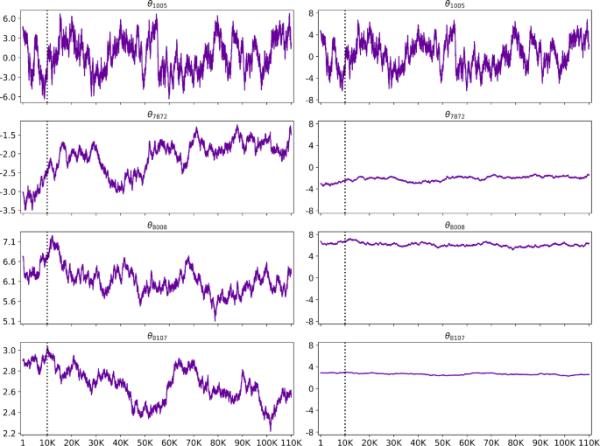
的4个参数坐标的马尔可夫链轨迹图,通过批量为3000的小批量FNBG采样拟合到MNIST上。每行显示同一条链的单个参数的两条轨迹图;右边的跟踪图比左边的更缩小。右列的示踪图在垂直轴上共享一个公共范围。垂直虚线表示燃烧结束
可以观察到,无论网络深度如何,放大的轨迹图(图5的左列)都没有表现出局部模式的夹持,这与表5的非消失接受率一致。此外,从缩小的示踪图(图5右列)中可以看出,链尺度在较深的层中减小。例如,参数(输出层)的右侧轨迹图在y轴范围内波动不明显,而参数(第一隐藏层)的右侧轨迹图在相同的y轴范围内波动更大。
图5表明,较浅层的参数链进行更多的勘探,而较深层的参数链进行更多的开采。这样,随着网络深度的增加,链规模向点估计方向崩溃。
对于图6a所示的每个批大小,在从MNIST训练集中抽取的10个批样本上评估Eq.(3.3)的似然函数。然后从10个对数似然值生成一个箱线图,如图6a所示。对数似然函数按批大小归一化,以便在不同批大小之间获得视觉上可比较的箱线图。在PyTorch中,标准化的对数似然是通过用reduction=' mean '初始化的CrossEntropyLoss类计算的。在每个箱线图中,蓝线和黄点对应于10个相关对数似然值的中位数和平均值。水平灰线表示基于整个MNIST训练集的对数似然值。图6b是使用FMNIST训练集生成的,遵循类似的设置。
图6
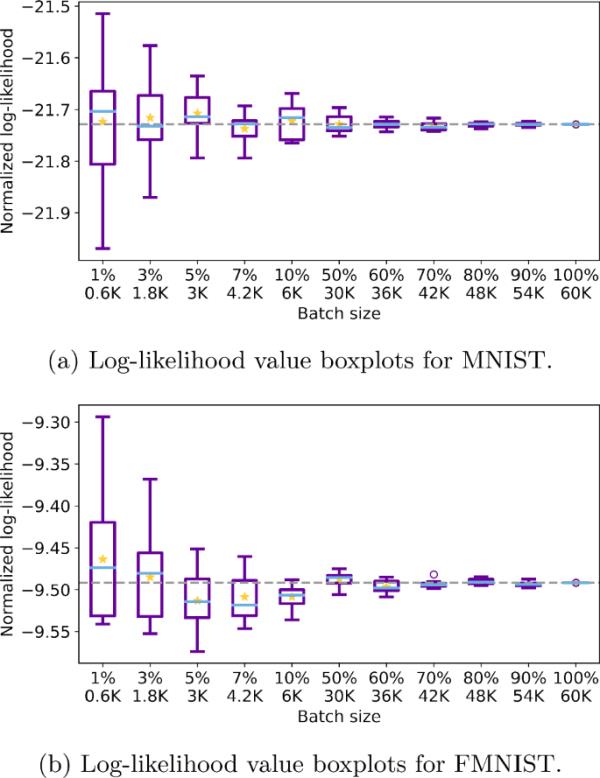
MNIST和FMNIST的归一化对数似然值的箱线图。每个箱线图总结了给定批大小的10批样本的归一化对数似然值。为了规范化,每个对数似然值除以批大小。蓝线和黄点对应中位数和平均值。水平灰线表示批大小等于训练样本大小的精确对数似然值
图6a和6b表明,对数似然值随着批大小的减小而变得越来越不稳定。此外,当批大小接近训练样本大小时,对数似然值的波动性消失。因此,图6直观地证实,近似似然倾向于增加批大小的确切似然。因此,FNBG取样的批量大小最好尽可能大,直到(更细的)块接受率不会变得低得令人难以置信。
图7探讨了网络深度如何影响近似MCMC的预测精度。浅层包含1个隐藏层,深层包含6个隐藏层,使用batch大小为100、proposal方差为0.04的minibatch NBG拟合到带噪声的XOR训练集;每个mlp都实现了链。随后,在带噪异或测试集上评估每条链的预测精度。每组10条链生成一个箱线图,如图7所示。蓝线代表中位数。
图7
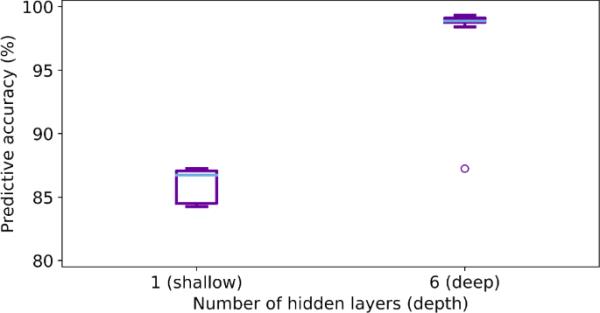
浅层和深层MLP体系结构之间的比较。每一个都是通过100个批次的小批量NBG采样来适应有噪声的异或。预测精度箱形图由每个MLP的10个链生成。蓝线表示中位数
同样的10条链被用来生成图3b、图4和图7中的相关图。特别是图3b中最左边的箱形图和图7中最右边的箱形图来自相同的10条链,因此是相同的。图4显示了10条链上每个节点和每层的平均接受率,也产生了图7中预测准确性的正确箱线图。
和的预测精度中位数分别为和,如图7中蓝线所示,因此预测精度随深度的增加而增加。此外,图7的四分位数范围表明,更深层次的架构产生更少的波动性,并且在这种意义上更稳定,预测精度更高。作为一个整体的经验观察,在近似MCMC中增加网络深度似乎会产生更高和更少波动的预测精度。
增加前馈神经网络的深度可以提高预测精度,但会降低深层块的接受率。在更深层减少提案差异有助于抵消接受率的降低。增加初始层的网络宽度对接受率没有负面影响,相反,增加深度对接受率有负面影响。
本小节从经验上评估批大小对近似MCMC预测精度的影响。为此,采用批大小分别为600、1800、3000和4200的小批FNBG采样方法拟合MNIST和FMNIST训练集,分别对应于每个训练样本大小的、、和。每个训练集和批大小的组合实现一个链。表2报告了每个链的预测精度。
同样的链用于计算表2中的预测准确性以及“附录C”表5和表6中的接受率。产生MNIST和批量大小为3000(表2的第一行和第三列)的预测精度的链部分通过图5中的示踪图显示出来。
根据表2,使用3000个批量大小可以获得MNIST和FMNIST的最高精度。总的来说,预测的准确性随着批量大小的增加而增加。然而,当批大小从3000增加到4200时,预测精度下降;这可以解释为4200的批大小太大,从某种意义上说,它降低了接受率(见表5和表6)。因此,正如第5.4节所指出的那样,调优指南是将批大小增加到不会大幅降低细块接受率的程度。
在MNIST上获得的预测精度表明,非收敛链(通过小批量FNBG模拟)从数据中学习,因为基于纯粹机会的数据不可知猜测的预测精度为。虽然深度学习的随机优化算法的预测精度高于MNIST,但这项工作的目标并不是构建一个在预测方面优于随机优化的近似MCMC算法。主要目标是证明神经网络的近似MCMC从数据中学习,并揭示相关的采样特征,例如随着网络深度的增加,链范围的减小(图5)和接受率的减小(表5和表6)。文献中已经报道了使用哈密顿蒙特卡罗进行深度学习的类似预测精度(Wenzel et al. 2020;Izmailov et al. 2021)。尽管如此,相关工作的主体依赖于短一到两个数量级的链长度;例如,Izmailov等人(2021)在每个链实现中运行了多达900次迭代。本文提出通过将神经网络参数分组到更小的块中来避免消失的接受率,从而能够生成更长的链。
表2通过不同批大小的小批FNBG采样拟合MNIST和FMNIST得到的预测精度
在对前馈神经网络参数进行小批量MCMC采样时,增加采样批量可以提高预测精度。这个观察结果是可以预料到的,因为当批大小等于训练样本大小时,小批量MCMC就会变成精确的MCMC。然而,批量大小可以增加到验收率没有显著降低的程度。
需要提醒的是,在本文的实验中,每条链运行110000次迭代,其中前10000次迭代被丢弃为燃烧。最后(剩余100000次)迭代用于通过基于Eq.(3.6)的贝叶斯边缘化进行预测。在Eq.(3.6)中只使用了10000次迭代来限制预测的计算成本。
由于Eq.(3.6)的近似后验预测pmf可以根据蒙特卡罗迭代和测试点并行计算,因此存在一个易于处理的贝叶斯边缘化解。这种并行解决方案的实现被推迟到未来的工作中。
同时,本文还研究了链长对预测精度的影响。按照这些方法,通过minibatch FNBG实现的最后1000次、10000次、20000次和30000次迭代来计算预测精度,每个批次的MNIST和FMNIST都为3000次(见表3)。同一条链的最后10000次和所有100000次燃烧后迭代分别产生表2中的预测精度和表5和表6中的接受率。
表3不同链长得到的预测精度
表3表明,随着链长度的增加,预测精度增加(对于MNIST和FMNIST)。因此,当链遍历神经网络的参数空间时,尽管缺乏收敛性,但具有预测重要性的信息仍会累积。由表3还可以看出,随着链长的增加,预测精度的提高速度减慢。
尽管缺乏收敛性和缓慢的混合,但增加从前馈神经网络的参数空间采样的近似MCMC迭代次数可以提高预测精度。随着链长度的增加,预测精度的提高速度减慢。
为了评估数据增强对预测精度的影响,在MNIST和FMNIST训练集上进行了三种图像变换,即角度旋转、模糊和颜色反转。图像旋转的角度随机选择在和30度之间。每张图像模糊的概率为0.9。模糊是从大小的高斯核随机生成的。核函数的标准差在1到1.5之间随机选取。每张图像的颜色反转概率为0.5。“附录D”中的图10显示了MNIST和FMNIST训练图像的示例,这些图像根据所描述的转换进行了旋转、模糊或颜色反转。
这三种变换中的每一种都应用于整个MNIST和FMNIST训练集。随后,通过batch size为3000的minibatch FNBG对每个转换后的训练集进行拟合,建议方差如表5和表6所示。每个转换后的训练集模拟一条链。在相应的未转换的MNIST和FMNIST测试集上计算预测精度,如表4所示。此外,基于未转换的MNIST和FMNIST训练集的预测精度在表4的第一列中可用,如表2所述。
表4不同数据增强方案的预测精度
根据表4,如果执行数据增强,那么预测准确性会急剧下降。值得注意的是,数据增强对FMNIST具有灾难性的预测后果。这些实证结果与Wenzel等人(2020)的“脏似然假设”一致,根据该假设,数据增强违反了似然原则。
在增广数据存在的情况下,前馈神经网络参数的近似MCMC采样仍然是一个有待解决的问题。数据增强违反了似然原则,从而大大降低了预测精度。
近似MCMC通过贝叶斯边缘化实现预测不确定性量化(UQ)。这种原则性的UQ方法构成了深度学习中近似MCMC优于随机优化的优势。本小节展示了如何通过小批量FNBG采样来量化神经网络的预测不确定性。
回想一下,为了计算表2中第3列的预测精度,我们对MNIST和FMNIST分别模拟了一条链(参见5.6节)。这些链用于估计相应测试集中部分图像的后验预测概率,如图8所示。图8中所有的测试图像都通过贝叶斯边缘化得到了正确的分类。
图8
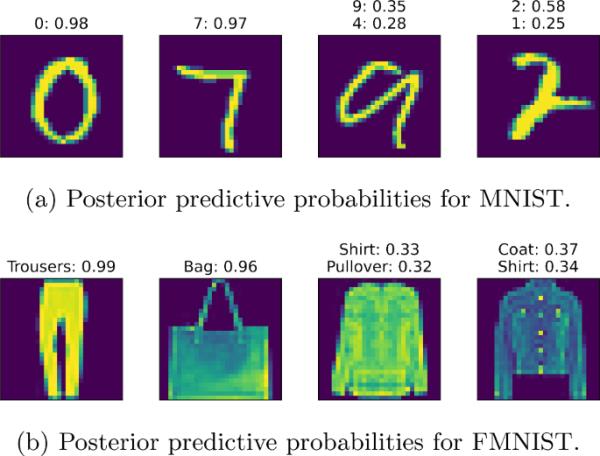
一些正确分类的MNIST和FMNIST测试图像的UQ演示。显示与低不确定性相关的每个图像的最高后验预测概率,而显示与高不确定性相关的每个图像的两个最高后验预测概率
图8a中的第一和第二MNIST测试图像显示数字0和7,对应的后验预测概率为0.98和0.97,表明分类结果接近确定。图8a中的第三个MNIST测试图像显示了数字9。试图用眼睛对这张图片进行分类会使人怀疑图片中的数字是9还是4。虽然贝叶斯边缘化正确地将数字分类为9,但后验预测概率相对较低,表明预测存在不确定性。此外,第二高的后验预测概率将数字4确定为可能的替代方案,与人类的感知一致。总而言之,后验预测概率和人类的理解在感知到的预测不确定性和合理的分类结果方面是一致的。关于UQ结论,图4与图8a的图3对齐。
图8b包含FMNIST测试图像,从UQ的角度类似于图8a。在图8b中,FMNIST测试图像1和2显示了裤子和袋子,相应的后验预测概率分别为0.99和0.96,表明分类结果接近确定。图8b的第三张FMNIST测试图像显示了一件衬衫。从视觉上看不清楚这幅图描绘的是衬衫还是套头衫。虽然贝叶斯边缘化正确地将物体识别为衬衫,但后验预测概率和捕捉人类的不确定性并确定两种最合理的分类结果。在UQ结论方面,图4与图8b的图3类似。
通过前馈神经网络参数的近似MCMC采样实现非收敛链可以帮助有意义地评估预测不确定性,这与人类的见解是一致的。
下载原文档:https://link.springer.com/content/pdf/10.1007/s11222-023-10285-5.pdf



